The Engine Behind Parcel-Sense
Today, Parcel-Sense operates as a high-scale geospatial engine that provides "Detection Plus." We’ve moved past the era of a single model guessing at a pixel. Instead, we deliver a lead that has been double or triple-verified by a coordinated stack, giving a human reviewer everything they need to prioritize review of detection.
The strength of Parcel-Sense comes from coordinating multiple models designed to reduce noise and improve review prioritization. We didn't build a four-model stack because we wanted complexity; we built it because the real world is messy, diagonal, and full of "noise" that breaks traditional AI.

Our Foundation: A 150,000-Image Data Moat
The core of our intelligence is a dual-ensemble CNN architecture trained on a massive, proprietary dataset of 150,000 parcel-masked images. This is the engine’s "experience," allowing it to generalize across a wide range of real-world conditions.
While high accuracy is a technical triumph, in the world of assessments it creates a sea of 'true' detections that only begin to tell a third of the story and sometimes less.
Identification Without Context
Below are two parcels, one of which is vacant and the other improved with all improvements recorded.


Here is a parcel assessed as vacant land with a garage.

Lastly, a building on Cook County parcel 2929205021, with a 2025 Assessor Certified assessed building value of $221,075 which per aerial imagery appeared occupied in 2017 but remained assessed as vacant land until its detection in 2025.

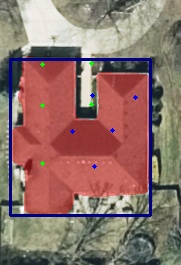
In all of these cases the CNN models will predict confidently the same thing, that the parcel has an improvement. It cannot provide how big it is, if the building is across two parcels, nor if there is more than one improvement on the parcel.
So we set out to build layers to give context to the detections.
Yolo Structure Detection
Early approaches leaned on YOLO to be our contextual anchor, YOLO was trained in two specific categories: "House" and "Garage". It seemed logical at first, but we realized that identifying a "House" vs. a "Garage" from overhead imagery is a subjective trap. To a model or even a human at a 6-inch resolution, a roof is a roof. As we expanded trying to force a model like YOLOv8 to act as a blanket classifier across dozens of building types wouldn't reliably scale and would lead to "hallucinated" labels.
We made the decision to move YOLO to a single class: "Structure." We stripped away the guesswork and turned YOLO into a high-confidence locator.



Even to this end we hit the ceiling of what a detection bounding box can do. Parcels aren't perfect squares aligned to cardinal directions. When a building sits diagonally, a YOLO bounding box is forced to include driveways, parking lots, yards, roads, and sidewalks just to fit the roof inside.
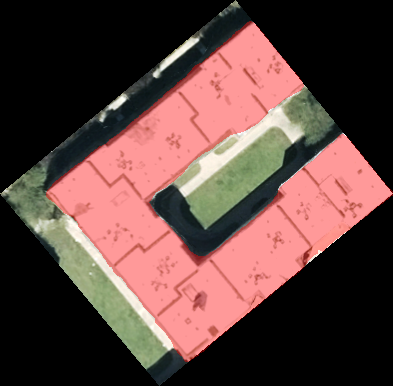
DeepLabV3+ Segmentation
To overcome the "box" limitation, we engineered a Semantic Segmentation layer, DeepLabV3+. This allowed us to stop looking at boxes and start looking at pixels. Instead of a box that includes the yard, we extract the precise building features.
Reviews now know if they are looking at a detection estimated 500 sq. ft. or 3,500 sq. ft. providing more context than any label ever could.




A Tandem Architecture
Today, these models work in a tandem that compensates for individual weaknesses:
- The Dual-Ensemble CNNs trained on our 150,000-image data moat provide the high-confidence identification of whether a parcel is improved or not.
- If the CNN is uncertain due to shadows or camouflage, the system looks for an agreement from YOLO and a pixel-mask from the Segmentation model.
- If segmentation identifies a footprint inside the bounding box, the system bridges the gap that a single model would have missed.
Our system is designed to extract spatial signals related to structures, footprint size, and parcel adjacency, how big it is, and flagging where it relates to surrounding parcels leaving the final judicial "what" to the human who now has the data to decide in seconds.
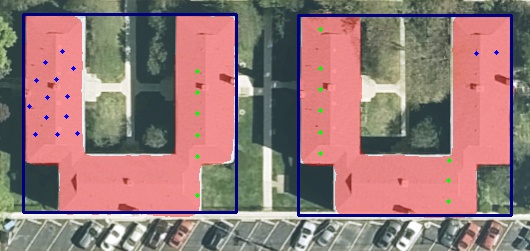
Evaluating Adjacency
In this case, Parcels A+B are evaluated together. Result: The system may identify structures extending across multiple parcels to flag to you that it maybe explainable by adjacent parcels.
Swipe sideways to view full comparison




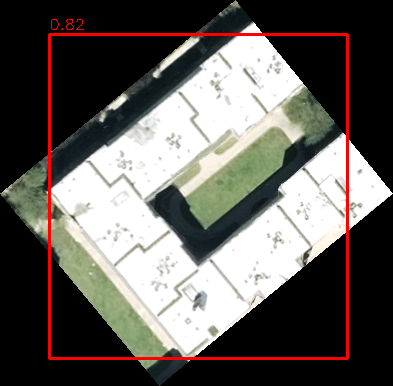
Segmentation Metrics

The segmentation model estimates a garage footprint of approximately 591 sq. ft.
What remains is the industrial improvement below, where the segmentation model identified an estimated 40,000-square-foot footprint fully contained within the YOLO detection area, producing a strong multi-model agreement signal.

We Are Not Without Our Limitations
Parcel-Sense operates on high-resolution aerial imagery, and while the system is designed to extract reliable, reproducible signals at scale, it remains bound by the physical realities of the world it observes.
Occlusion from Natural Cover
Tree canopy, shadows, and seasonal variation can obscure structures from overhead view. In these cases, even high-resolution imagery may not fully expose the underlying features. While the system is trained to recognize patterns through partial visibility, complete obstruction limits what any aerial-based approach can confirm.
Resolution and Scale Constraints
The system operates at approximately 0.5 feet per pixel. Parcels or features that approach or fall below this scale such as extremely narrow or irregular geometries may not be meaningfully represented in the imagery. For example, a parcel that is only a fraction of a pixel wide in one dimension cannot be reliably interpreted, regardless of model performance.
These constraints are not unique to Parcel-Sense, but inherent to aerial observation itself. For this reason, the system is designed to surface high-confidence, explainable signals where the data supports it, while leaving final determination to human review when the underlying imagery is physically limited.
Predictive not Conclusive
Parcel-Sense is an analytical review-assist platform intended to surface candidate detections for human review. Outputs are predictive and should not be treated as definitive assessment, legal, or property determinations.